

Building a Lambda Architecture with Druid and Kafka Streams
At FullContact, engineers have the opportunity to solve the unique and challenging problems created by a growing Identity Resolution Business. The start to any good solution is researching the tools your team is familiar with, along with the vast array of solutions out in the open-source world. This blog will outline our use of Apache Kafka and Druid and how we added Kafka Streams to the stack in order to solve a new problem.
The Problem
FullContact needs to keep track of every API call and response that a customer makes, along with the types of data returned in each response. This data is used for billing and analytics. Customers need to be able to see how much data they are using, and FullContact needs to ensure that the usage remains within the contracted limits. We needed a system that could track usage for analytics, limiting, billing, and a system that could store the contractual agreements and limitations on each customer account.
Many of these features were being implemented by a third-party API management solution we were using, but due to scaling challenges and feature limitations, it was time to move on and build our own. On the technical side, we needed a system that was scalable and fast.
Last Year’s Solution
In order to solve the problem, we chose Kafka and Druid. For a more in-depth look at the solution, you can take a look at our previous meetup talk and blog post. At a high level, the solution looks like this:
- Each call to a FullContact API results in an Avro usage message sent to Kafka that has the details of each request (any sensitive details are encrypted with a unique key).
- Druid consumes the usage topic for real-time ingestion and querying.
- Secor consumes the usage topic for long term archiving to S3 in parquet file format.
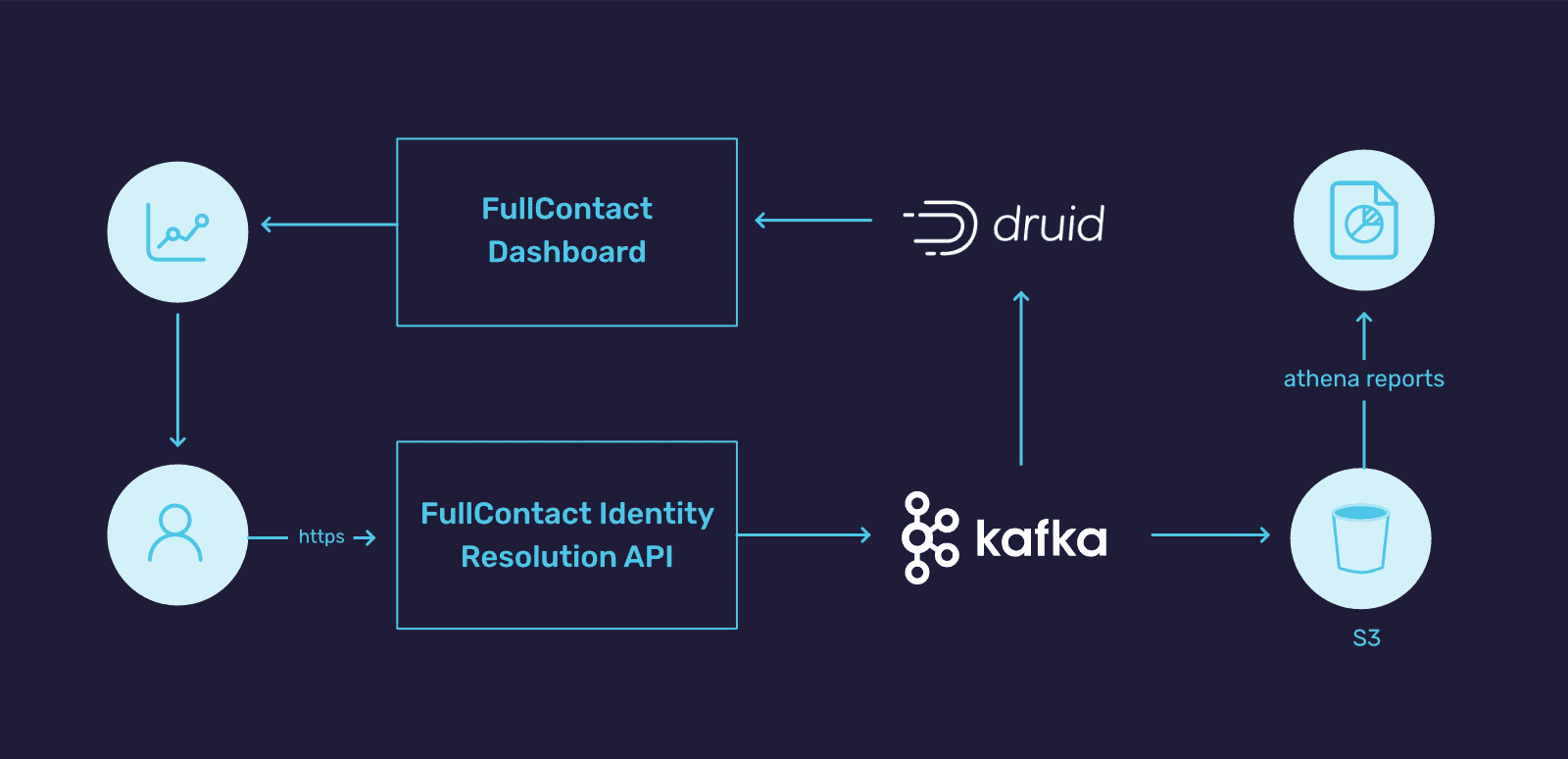
Using the framework above we were able to provide several useful tools to our customers and internal stakeholders:
- A realtime dashboard that instantly reflects new usage and shows patterns over time.
- Powerful internal reporting and insight through the open source tool Turnilo.
The New Problem
Now that we had a way to keep track of usage and describe the limits for each client, we needed something that would automatically enforce those limits in close to real-time.
Here are a few of the requirements that influenced our decision to leverage Kafka Streams:
- Adjusting service to each client should happen nearly instantaneously when they reach their specified limit.
- Checking limits should be done in an asynchronous manner, no additional latency or complexity is introduced into the API serving layer.
- The component keeping track of real-time aggregations should be able to be restarted and easily restore the previous state.
- We should not overload our existing Druid cluster by querying it for current usage on every API request.
To solve this problem we came up with a solution that resembles a lambda architecture. In our case, instead of having a batch method and stream method, we have Druid with real-time ingestion for historical aggregation and Kafka Streams for our stream processing and real-time eventing engine.
As a quick introduction, here is the official description of Kafka Streams from its website:
“Kafka Streams is a client library for building applications and microservices, where the input and output data are stored in Kafka clusters. It combines the simplicity of writing and deploying standard Java and Scala applications on the client-side with the benefits of Kafka’s server-side cluster technology.”
When our Kafka Streams app initially starts up and starts to aggregate the number of usage events for a client, it has no concept of any historical usage that occurred before that time.
In order to get that view of the world, it queries Druid to return an aggregated count of all usage that occurred since the client’s contracted start date to “now” (the current timestamp in the stream where aggregation started). As additional usage rolls in, the streams app continues to update the aggregation and emits new events to downstream topics when the client has reached their usage threshold.
The current aggregated usage number for each client is persisted in Kafka Streams state stores. Any subsequent restarts result in automatic recovery of the aggregated counts from the state store instead of a re-query to Druid.
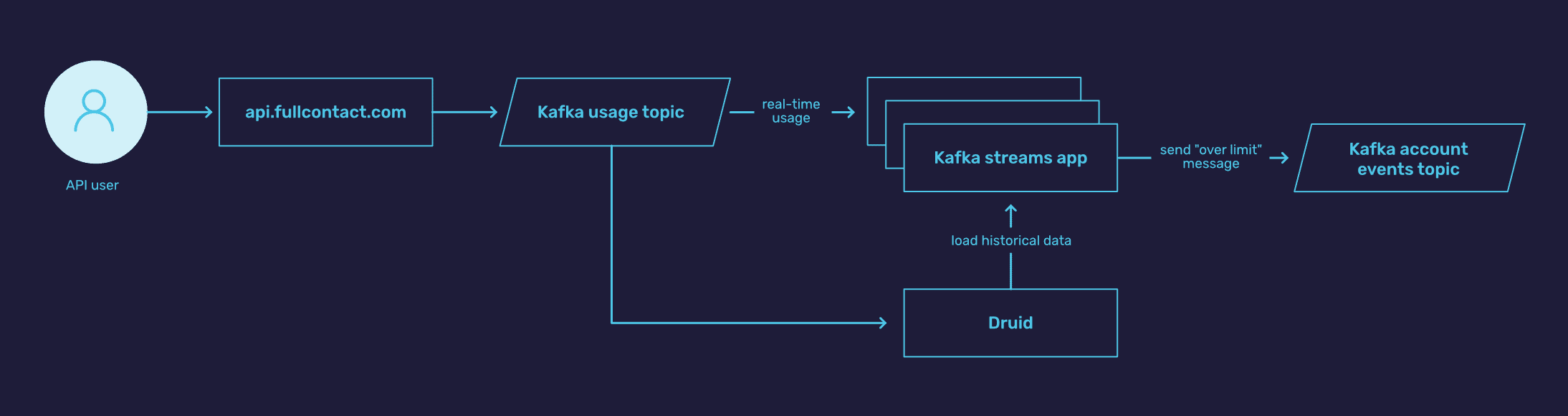
Features in Kafka Streams:
We made use of a lot of helpful features from Kafka Streams in order to build this solution:
- Exactly-once processing helps us ensure we only process a usage message once so we are not overcounting or missing messages even if there are failures or latency in the system.
- RocksDB state stores persist the aggregation results on the local disk and also allow for clean recovery by backing up state to the Kafka broker
- The Kafka Streams deployment model is incredibly simple. It’s just a JVM app so it can be deployed like you would any JVM app and doesn’t need a specialized streaming cluster like Storm, Flink, Spark, etc. We used our normal approach of deploying our app as a Docker container managed by a Kubernetes.
Challenges We Faced
As happens when you start using any new technology and start to scale we met a few challenges along the way.
Kafka Transactions
Kafka transactions were a new feature introduced in KIP-98 that Kafka Streams uses to ensure exactly-once processing. As your stream processing topology is running, it will commit each transaction. If transactions are not committed in a timely manner, the broker will “Fence” (ProducerFenceException) and a rebalance will be caused. We found this out the hard way when a few parts of our topology had bottlenecks and inefficiencies that caused us to go into an endless rebalance loop.
Whenever the rebalances started happening it became difficult to know which stream threads were assigned to which partitions and if a particular thread was the culprit. Here are a few simple scripts we used to help shed light on this:
bin/kafka-consumer-groups --bootstrap-server $MSK_BROKERS --describe --group stream.topic.prod.stream.v3 | ./parse_partition_assignments.py Host: /10.2.69.5, stream.topic.prod.stream.v3-2d800eba-776f-4e8e-801b-6060c706d279 Threads: 1: ['databus.stream.usagetopic.v0', 'stream.topic.cpuc.v2', 'stream.topic.internal.contracts.v0'] 2: ['stream.topic.load.contract.v0'] 3: ['stream.topic.prod.stream.v3-aggregated-usage-repartition'] Host: /10.2.112.202, stream.topic.prod.stream.v3-e4788e3f-864d-45c5-9174-6168207a4c7f Threads: 1: ['databus.stream.usagetopic.v0', 'stream.topic.cpuc.v2', 'stream.topic.internal.contracts.v0'] 2: ['stream.topic.load.contract.v0'] 3: ['stream.topic.prod.stream.v3-aggregated-usage-repartition'] Host: /10.2.112.124, stream.topic.prod.stream.v3-a44ecbbc-0023-49d3-b866-88d8157585e0 Threads: 1: ['databus.stream.usagetopic.v0', 'stream.topic.cost.v2', 'stream.topic.internal.contracts.v0'] 2: ['stream.topic.load.contract.v0'] 3: ['stream.topic.prod.stream.v3-aggregated-usage-repartition']
Topologies and the Monostream
Similar to the outcast monoservice, the monostream is what happens when you let your Kafka Stream start to take on too many responsibilities. The topology directed acyclic graph (DAG) that represents the aggregation logic quickly becomes unwieldy. This can make it difficult to reason how data flows through your topology and to determine where the possible bottlenecks and issues are. While inarguably the best solution to this is to just keep your stream app simple, visualizing your DAG can often help as well.
The Kafka Streams API has a description and toString method that will produce a text output of your DAG.
topology.describe().toString();
If you take the output of that and plug it into the online Kafka Viz App created by Joshua Koo (@zz85).
Here is an example topology description from a getting started Udemy Course:
Topologies:
Sub-topology: 0
Source: KSTREAM-SOURCE-0000000000 (topics: [favourite-colour-input])
--> KSTREAM-FILTER-0000000001
Processor: KSTREAM-FILTER-0000000001 (stores: [])
--> KSTREAM-KEY-SELECT-0000000002
<-- KSTREAM-SOURCE-0000000000 Processor: KSTREAM-KEY-SELECT-0000000002 (stores: []) --> KSTREAM-MAPVALUES-0000000003
<-- KSTREAM-FILTER-0000000001 Processor: KSTREAM-MAPVALUES-0000000003 (stores: []) --> KSTREAM-FILTER-0000000004
<-- KSTREAM-KEY-SELECT-0000000002 Processor: KSTREAM-FILTER-0000000004 (stores: []) --> KSTREAM-SINK-0000000005
<-- KSTREAM-MAPVALUES-0000000003
Sink: KSTREAM-SINK-0000000005 (topic: user-keys-and-colours)
<-- KSTREAM-FILTER-0000000004 Sub-topology: 1 Source: KSTREAM-SOURCE-0000000007 (topics: [user-keys-and-colours]) --> KTABLE-SOURCE-0000000008
Processor: KTABLE-SOURCE-0000000008 (stores: [user-keys-and-colours-STATE-STORE-0000000006])
--> KTABLE-SELECT-0000000009
<-- KSTREAM-SOURCE-0000000007 Processor: KTABLE-SELECT-0000000009 (stores: []) --> CountsByColours-sink
<-- KTABLE-SOURCE-0000000008
Sink: CountsByColours-sink (topic: KTABLE-AGGREGATE-STATE-STORE-0000000010-repartition)
<-- KTABLE-SELECT-0000000009 Sub-topology: 2 Source: CountsByColours-source (topics: [KTABLE-AGGREGATE-STATE-STORE-0000000010-repartition]) --> CountsByColours
Processor: CountsByColours (stores: [KTABLE-AGGREGATE-STATE-STORE-0000000010])
--> favourite-colour-output
<-- CountsByColours-source Processor: favourite-colour-output (stores: []) --> none
<-- CountsByColours
When plugged into kafka-viz it will produce a sketch of your topology:

Kafka Streams apps (and normal Kafka Consumer Groups) have an automatic way to handle members of the group coming or going. Whenever a new member is detected, processing pauses while a rebalance occurs and Kafka partitions are redistributed and assigned to the new members.
While this is great for handling the occasional crash or restart, it’s less than ideal when it happens every single time you deploy a new version of your application.
With Kubernetes Deployments, the default deployment strategy is a RollingUpdate. This deployment strategy ensures that a new instance of the application is only added one by one, and old instances are only killed one by one after each new instance declares itself healthy. When you’re running a REST service that always needs to respond to traffic this is a great way to ensure you always have a minimum number of healthy apps to serve traffic. When you’re deploying a new instance of your Kafka Streaming app, it is a recipe for pain as the rebalance process occurs during every single step of the above process.
Really what we want in the case of deploying a streaming application is to cleanly kill all the old instances of the service, then add all of the new instances of the service at the same time, allowing them to rebalance once. Luckily Kubernetes lets us do this by specifying Recreate as the deployment strategy:
.spec.strategy.type==Recreate
Recap and the Future of Our Streaming Data Journey
As a quick recap, we started out simply wanting to capture all of our API usages and use it for analytics. Druid and vanilla Kafka does that nearly out of the box. When we needed to build a real-time eventing system that reacted continuously based on updated aggregation counts we chose Kafka Streams for the job. While it worked well, it did take a bit of learning and we most likely inadvertently created a bit of a monostream that we will be forced to continue to maintain or refactor. But hey, it does the job!
When we aren’t busy maintaining or refactoring here are a few tools out there we would like to spend more time learning about and applying to future problems if they fit.
New features in Druid 0.19 – we have been running Druid 0.16 for a little longer than ideal and look forward to the new features like JOINS, vectorized queries, and more!
ksqlDB – provides a database-like API to Kafka streams and KTables
Apache Pulsar – cloud-native distributed messaging platform alternative to Kafka which has its own concept of stream processing (Pulsar Function).
Thanks for reading, and keep an eye out for new learnings, hackathons, and blogs around these in the future.

