

What’s in a Name: How We Overcame the Challenges of Matching Names and Addresses
Identity Resolution is core to everything FullContact does. For the Identity Resolution team, that means translating contact fragments from multiple sources into a unique identifier for a person. Customers may also have various contact information for their customers including names, addresses, emails, phone numbers, and more. Using one or all of these elements, we aim to identify the person that contact represents.
Early versions of our Identity Resolution system worked primarily based on the exact matching of individual contact fields, which were then combined into a final matching score. Such an approach works fairly well with fields like email addresses, phone numbers, and many online identifiers. However, as we shifted towards providing Identity Resolution based on name and address input, things needed to change for a couple of reasons. First, names and addresses taken individually often match to too many candidate records to be efficient. And second, both names and addresses come in many variations, not all of which can easily be standardized.
Phase 1
To address the first issue, we took the approach of querying with the name and address in combination. This manifested as a simple name/address key. To address the second issue, this new key was created from a highly-normalized address “fingerprint” along with the name data. The address fingerprinting was aimed at removing certain variability while retaining enough information to form a good (uniquely identifying) key in combination with the name.
An example might look like this:
first,last|1234mainst
This new name/address key was then folded into our existing exact-match approach. This new key only worked up to a point though, because we then needed to account for variations on first names, including things like nicknames or formal names. To handle this issue, we expanded incoming queries for name and address to the corresponding nicknames and formal names which would allow us the best chance for matching.
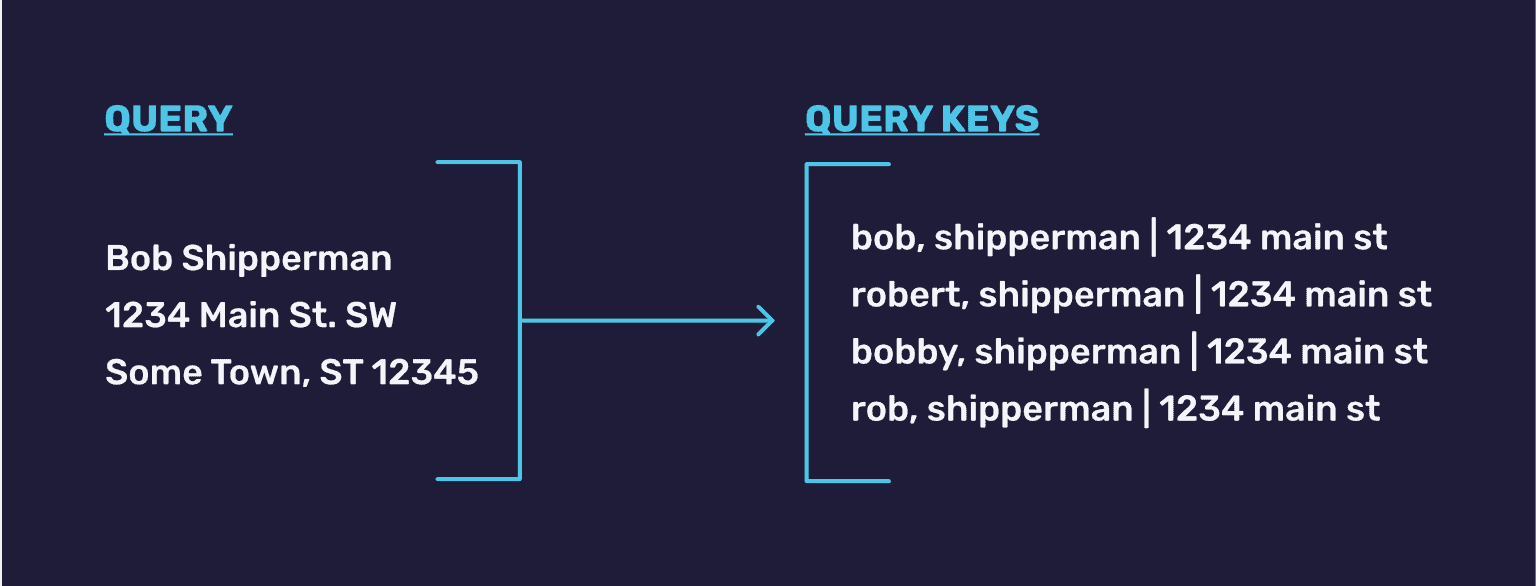
While this approach worked, it still didn’t fully solve the issue. We still wanted to improve our ability to handle edge cases, including misspellings and other minor errors. Attempting to predetermine all possible variations and bake them into keys for exact matching is clearly not scalable. Also importantly, we desired a framework that would allow for improving our capabilities more easily in the future.
Phase 2
To address the handling of edge cases that naturally occur in name/address data we went looking for an approach that would build upon the name/address keys we already had along with meeting our design constraints. There are several ways to solve the problem of matching data such as name and address. A common one is a rules-based system, which includes numerous rules defined for each edge case and match by iteratively applying some or all of the rules. Another prominent approach is based on Blocking and Filtering techniques.
For us, the first approach has a few drawbacks. First, it’s somewhat difficult to align these types of rules to our identity graph implementation while still maintaining the flexibility of the system itself. The second drawback is scale. We have scale requirements such that we must service Identity Resolution queries at high volume and in real-time. Given these constraints, we went with a solution modeled after the second approach. This would serve to strike a balance between performance and complexity.
We broke the problem down into two parts. The first, to develop a key to identify candidate matches. And the second, to choose the correct match from that set of candidates.
Again, we wanted to capture a single key which would work with a single lookup when matching on name and address data. Since the complexities of name data are different from address, we started there. Accounting for issues such as common misspellings, nicknames, and householding issues, the strategy relied on minimizing the information in the name key to match as many candidates as possible while also keeping the average number of candidates small. To accomplish this we might have devised a name key using only the first initial and the consonants of the last name.
For example, the name Chip Shipperman becomes cshpprmn.
A key like this could allow us to catch common misspellings while also catching some of the edge cases. A common householding example is where the data contains both the spouses in the first name field.
| First Name | Last Name |
| Shirley/Chip | Shipperman |
Our original approach would not have matched to anything for this case. However, in this model, we might create a name key like sshpprmn and at least have a chance of matching to Shirley Shipperman. With a name key in hand, we moved on to develop an address key that would similarly cast a wider net to find match candidates.
Address data can contain many variations of terms, abbreviations, and misspellings. This results in different data which all refer to the same address. We devised an address key similar to the name key that would bias towards generating quality candidates while avoiding many of the issues present in address variations.
One such key might use a combination of the numeric parts of the address along with the consonants of the street name. In this way, we can have a single key that will match to many variations of the same address.
So 1234 Main St SW. Some Town, ST 12345 becomes 1234mn12345.
In this example, we’ve chosen to use only the numerics (street number and zip code) and only the consonants of the street name. This allows us to not have to worry about a whole host of address matching issues related to abbreviations of directionals or street names. As we’ll see, we will have to deal with some of the issues we’re sidestepping now, later down the line when we choose the most correct matches in our secondary algorithm.
As we did previously, we can now combine the name and address keys to create one key for name/address graph queries.
sshpprmn|1234mn12345
A query key like this allows us to query our graph and pull back all candidate name and address pairs. Once we have the candidate name and address pairs, we need to determine which of them is the correct match.
To do this we process each candidate with our secondary algorithm scoring each according to how well it matches the original query. For this, we’ll need the original name and address data from the query, as well as the original name and address data from the graph. The query side is straightforward as we have it in hand at query time. The graph side requires us to carry that data through to the result of the query. We accomplish this by returning the graph context along with the result. This allows us to add whatever we might need to the context and use it for advanced secondary comparisons.
For each candidate name and address pair in the result, we compare it with the query. We first compare the names, then we compare the addresses to determine a score for each. When we have a score for each component of the name and address pair we combine them to determine the overall score for each match from query to result. Next, we apply a threshold to rule out non-matches and return the best candidates.
Our secondary algorithm leverages various text-matching techniques to determine the score of the match of each component. We can use edit distance algorithms such as Levenshtein distance or Jaro distance. Along the way, we’ve been working with our Data Science team to help evaluate and define different algorithms.
This got us to the point of having a flexible framework within which we could experiment with new keys, algorithms, and thresholds in isolation. From here we could iterate and improve our matching over time.
Phase 3
With this framework in place, we can now easily experiment with query key and secondary algorithm variations. We’ve developed a rich suite of tests and paired that with a test set that we are constantly refining. This allows us to continuously measure algorithm performance and the impact of enhancements.
Additionally, this gives our Data Science team the ability to work on improvements and testing without requiring Engineering to get involved. They have been hard at work testing out various enhancements, including experimenting with replacing our current heuristic-based approach with a Machine Learning model trained on real data.
Of course, there are still challenges, even with this new approach.
For example, our graph still needs to be built with the query keys for lookup. Because of this, we have to rebuild the entire graph to implement a new key. This can be costly as our graph is incredibly large, and the process to build it requires many resources.
In the future, we’ll be experimenting with ways to pre-build query keys in the graph, so that they can be combined at query time to form new data combinations. For example, if we wanted to query by name and email, we could easily do this if match keys exist ahead of time for all data types in our graph.
One would simply have to form the correct query and develop the algorithm for choosing the best matches. This could allow us to have a very flexible and advanced query facility in the future.

