

Inferred Identity
Enhancing Identity Resolution Through Implied Data Relationships
At a high level, the most fundamental core of FullContact’s Resolve product relies on two stages of operation:
- connecting fragments of contact information together when we determine those fragments originate from the same person (the ‘identity graph build’ process)
- allowing our customers to query for an identity by inputting one or more pieces of contact information, and returning a consistent identifier if that information lies in one of our connected clusters from the graph build process (Resolve)
In an ideal world, we would have perfectly complete, accurate and overlapping contact information fragments for all queries our Resolve customers ever made. The technical underbelly of our graph build and Resolve execution processes could function flawlessly while remaining almost as simple as the twin bullet points above suggest.
Unfortunately, real-world considerations almost always include (but are definitely not limited to) complications such as:
- missing or incomplete contact information;
- misspelled or otherwise erroneous contact information; and
- correct and complete contact information for an individual that is nevertheless present in disjoint/unconnectable fragments.
Challenges like these require an ever-evolving, world-class Identity Resolution product to add implicit and inferred information to a foundation of explicit data connection and query logic. While our graph remains anchored in a bedrock of explicit relationships, substantial incremental qualitative and quantitative improvements rely on secondary and transitive inferences tested repeatedly and rigorously on complex connection topology between billions of data points.
Identity graph foundation: explicit data relationships
If we have high-quality, complete fragments of contact information for an individual, connecting that data during the graph build and querying the data from our Resolve product are straightforward actions.
In the graph build step, we seek out overlapping, unique combinations of data shared between multiple collections/fragments of contact information to justify coalescing those clusters into a single identity cluster and granting that cluster a FullContact Identifier (or FCID).
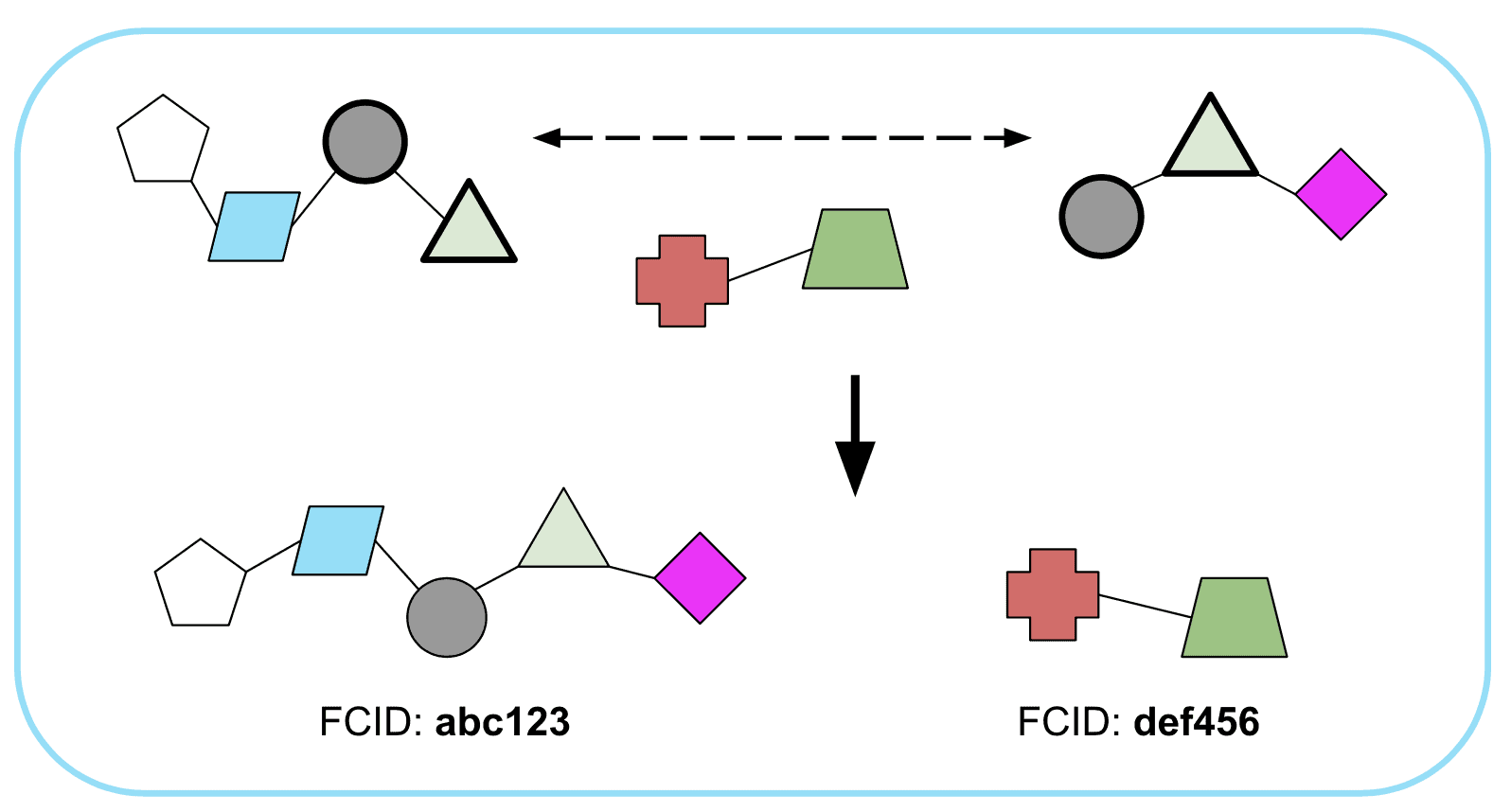
Figure 1. Graph build links smaller clusters of common identity by common contact info
When a customer uses our Resolve product to search for an identity by entering in one or multiple fields of contact information, we perform a series of computationally efficient key-value lookups to see if that contact information is present and attached to one of the identity clusters in our graph. If so, we return the associated FCID.
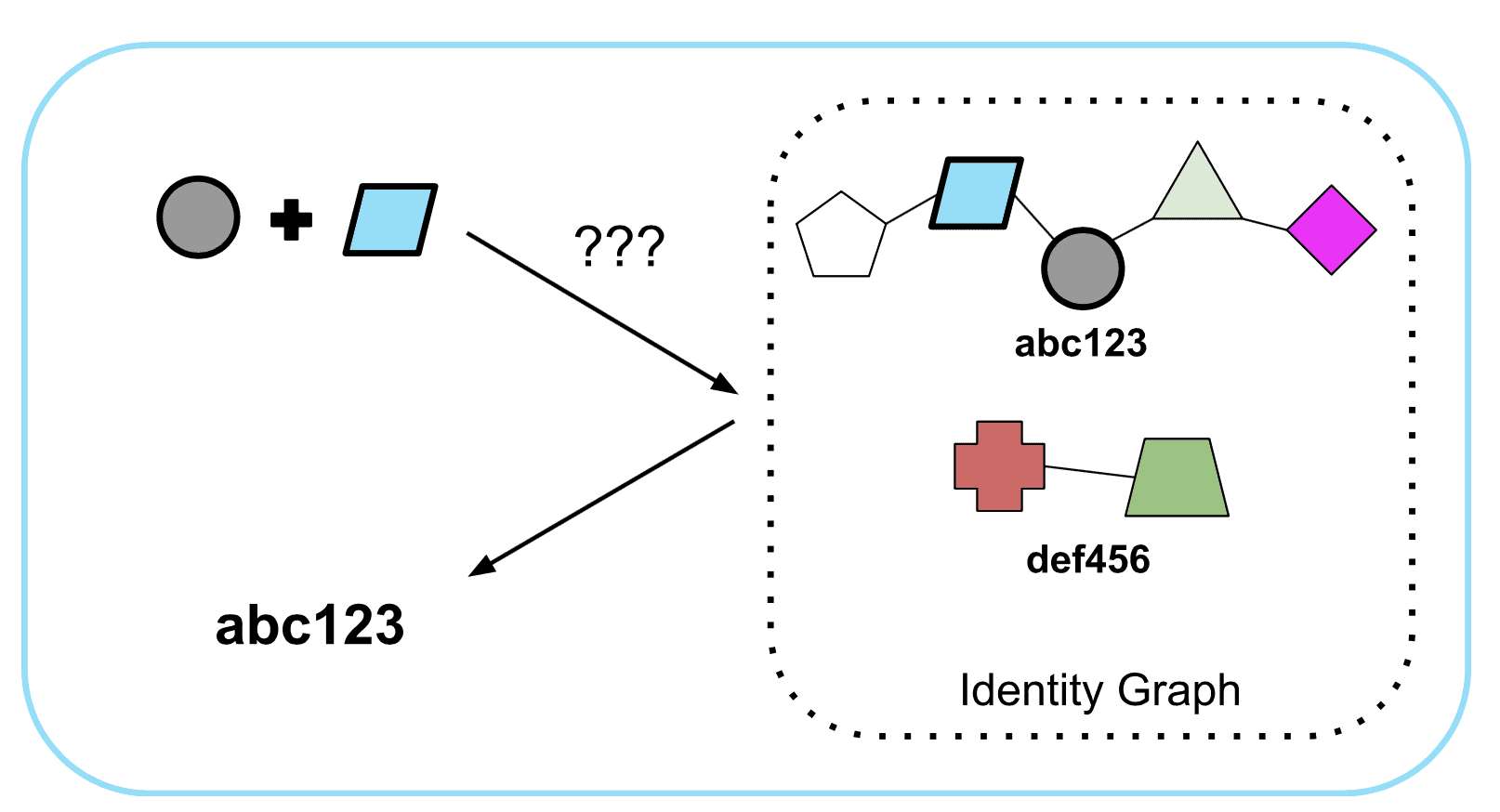
Figure 2. Query using several contact field values returns associated FCID to customer
Identity graph enhancement: examples of implicit data relationships and resolution
In cases of missing or disconnected/disjoint contact information fragments, we might sometimes accept the fact that we’re doing the best job we can and that we can’t match 100% of our customer queries to 100% correct identity clusters 100% of the time.
But if we assume fairly complete data (and connections thereof) as input to the graph build process, we can connect many disjoint identity fragments and resolve potentially problematic queries through reasonable inference.
In the case of the graph build, we might have two disjoint collections of contact information for Jane Smith at different addresses without enough unique shared data between them to justify their connection. But if Jane Smith fragment #1 is connected through residence at 123 Main Street to John Smith at 123 Main Street, and if Jane Smith fragment #2 is connected to 456 Second Street in the same city with the same John Smith, we can reasonably assume that Jane Smith #1 and #2 are the same person and connect those fragments.
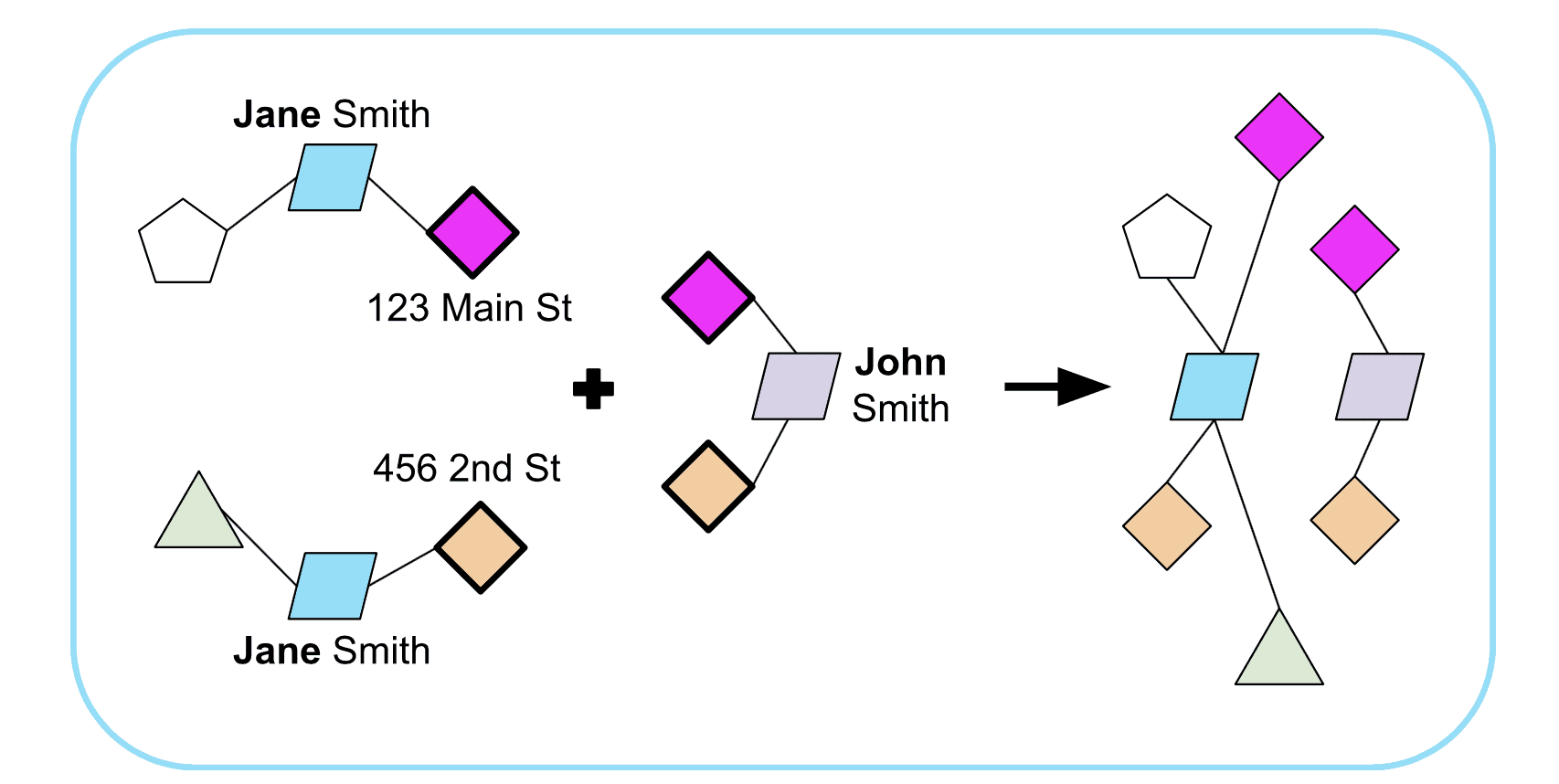
Figure 3. Inferring connection between contact fragments for Jane Smith through (presumed family member) John Smith’s shared addresses
Here, we’ve used a (likely) family relationship to infer connection between Jane’s identity fragments, even though those fragments were explicitly disjoint (or at least lacking enough shared information to confidently make a connection).
As another example: during a call to Resolve, a customer might query for a Jane Smith at 789 Monroe Avenue in zip code 12345. If this is the same zip code where we connected the Jane Smith fragments above, and if we know of no other Jane Smiths in zip code 12345, we can (with some prudent uncertainty) return the FCID for our (unique) Jane Smith in that zip code.
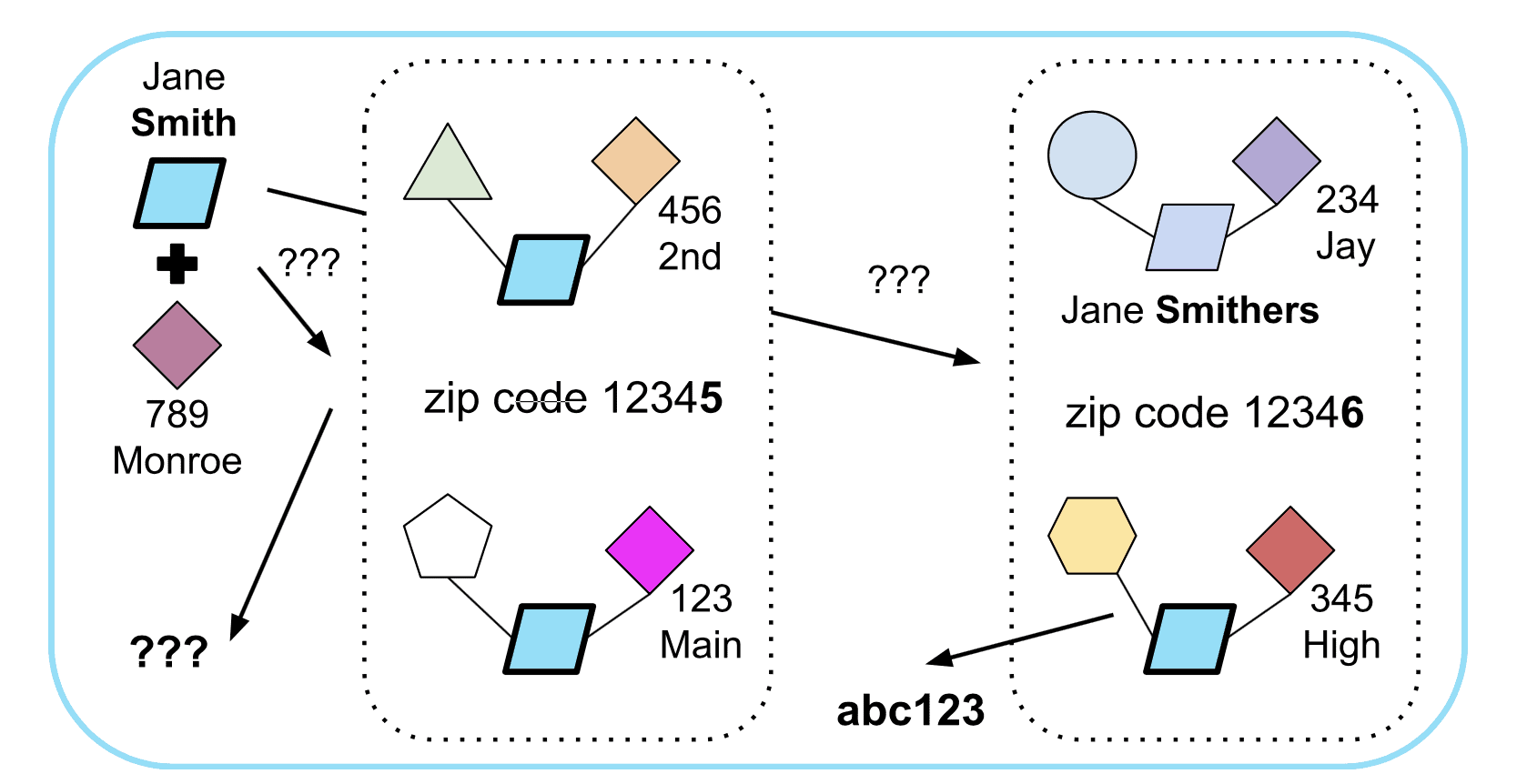
Figure 4. A query for Jane Smith at 789 Monroe in zip code 12345 can’t return an unambiguous result because 1) we don’t have an exact match for that name and address, and 2) the name isn’t unique in zip code 12345. On the other hand, we can return an inferred ID for zip code 12346 (where we don’t have an exact address match, but we DO know that only one identity within zip code 12346 has the name Jane Smith).
In the query example, we’ve leveraged:
- our knowledge that most household moves are geographically local;
- an assumption that we’re simply missing an address for Jane Smith; and
- an assumption that our having knowledge of only one Jane Smith in zip code 12345 means there is only one Jane Smith in that zip code.
Understanding considerations and risks
The last example (inferring a Resolve match at a missing address, given the queried name is unique in that geographic location) and its assumptions illustrate an important property of inferred identity connection and resolution: it certainly involves at least some risk and uncertainty.
In the case of inferred connection, we might scale confidence in our inference based on multiple ‘pivot points’ associated with the identity fragments we’re connecting (for instance, assigning greater confidence if Jane #1 and Jane #2 fragments are connected through the same John Smith identity at different addresses, or if that connection is bolstered by other family members Joshua and Jenny Smith as well).
When returning an inferred Resolve query result, we can scale our confidence based on extensive testing via methodologies such as a variation on dropout or cross-validation. We know our inference may (almost unavoidably) generate false positive results some of the time, but if we can relate those results with justifiable confidence levels, they can still generate quite a lot of incremental value for our Resolve product.
Relentlessly delivering and improving a world-class Resolve product
The continued evolution of our Resolve offering will depend on successfully synthesizing both explicit and implicit steps in our graph build and query handling. We continue to enhance both approaches with new techniques that fill gaps and add incontrovertible value. Look forward to more updates on this in the future!

