

Resolve: Building the Identity Resolution Engine (Part 3)
The following is the third installment of a multi-part series offering a glimpse of the behind-the-scenes advancements we achieved to deliver our Resolve API. The first post covered the origin of our Identity Graph and Resolve API, and in the second post, we delved into the power of our new persistent PersonID and the ability to Bring Your Own ID.
Part 3: Building Trust Through Security
To properly support our customers in this new era of privacy and security, we went back to the drawing board to invent new systems and patterns designed to maximize security around our customers’ data. Some of those patterns were in play in the previous posts with the engineered design of the PersonID.
Beyond IDs, we honed a centralized microservice to be the only system capable of encrypting and decrypting sensitive information. Being centralized eliminates the need to ever share the private keys with other microservices, thus limiting exposure of leaking the sensitive keys. 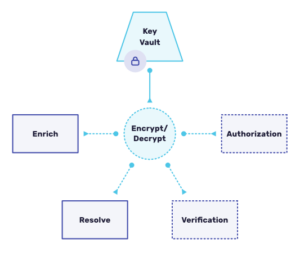
Being a centralized, purpose-built micro service adheres to Service Oriented Architecture philosophy, but also creates new challenges to surmount. For us, given the amount of places encryption and decryption are used we had to engineer this system to scale. As part of our batch remapping process to re-resolve archived person fragments, we needed it to work inside Spark jobs which couldn’t take days to run, metering out 1,000 requests a second.
No, we needed this API to handle volumes of 1,000,000 requests/second. As part of our Resolve release, we pushed the limits of our APIs and parts of AWS to achieve this. We created S3 wrappers that worked natively inside Spark, much like s3a://, and enhanced the decryption service to seamlessly autoscale up and down. The client and server were designed to block API calls and slowly increase the traffic until our decryption rate could be sustained at 1MM qps.
Specific to the Resolve API, as our customers provide us with their own identity fragments, we wanted to make sure we didn’t have their PII lying around in un-encrypted databases. We baked more security into our design by only retaining person fragments in an archived form. This eliminates the potential for using live queries to retrieve these fragments. To further add security to our customers’ data, using the above-discussed encryption service we encrypt each stream prior to archival with encryption keys unique to each customer. From a technical perspective, we felt that at this point our customers’ data was maximally protected.
Lastly, with the addition of accepting Record IDs (RIDs) and PersonIDs (PIDs) as input to our APIs, customers also benefit from the secure design of the API. Where a customer previously needed to send PII over the wire to enrich or resolve a record, an opaque identifier will now suffice. More specifically, if a Customer Record is loaded into the Resolve API with a RID, that RID is all that is required to perform an enrich query in person.enrich. We believe that with capabilities as simple as this we can slowly begin to increase general security within the industry.
In the final post of the series, we talk about the ways we try to achieve peak performance of our systems and discuss some of the technology choices we made on the backend. Thanks for reading and we’ll see you next week!

