

Resolve: Building the Identity Resolution Engine (Part 4)
The following is the fourth and final installment of a multi-part series offering a glimpse of the behind-the-scenes advancements we achieved to deliver our Resolve API. The first post covered the origin of our Identity Graph and Resolve API. In the second post, we delved into the power of our new persistent PersonID and the ability to Bring Your Own ID. The third post focused on building customer trust through security capabilities.
Part 4: Being API First and Choosing Our Bedrock
As any structural engineer will tell you, having the proper foundation to build from is paramount to the success of a project. Designing and engineering scalable and performant APIs is no different–and if you’re an API-First company like FullContact, you’d better be good at it!
The release of Resolve API and MAID capabilities are taking us into a new world inching closer to the realm of AdTech. Industry roughly dictates being able to sustain sub 80ms response time at high volumes, where the best can achieve 15ms and millions of requests a second.
To help us achieve these performance characteristics, we leverage Scala and Java8 for our APIs, DropWizard for the scaffolding, prefer asynchronous call flows with HTTP clients and Kafka, and utilize modern scalable databases such as Cassandra and HBase.
Generally, databases tend to be the primary source of bottlenecks and while we had used HBase for other systems and processes such as our Data Onlining and Enrichment services, we diversified and elected to move to Cassandra. Currently, we have Cassandra 3.11.5 powering our Resolve DB, and leverage Virtual Nodes (vnodes) to simplify our scaling procedures. Cassandra also offers simpler and familiar query syntax with CQL, and it’s schema definitions allow clever and efficient ways to organize your data between partition and clustering keys. With Cassandra, it also has a more performant and theoretically “Super-charged Sister” with Scylla, which could offer more headroom for shaving off millis.
Once we had the Resolve API assembled, we wanted to ensure we hit the targets we set out to achieve – benchmarking your API is the simplest way to understand these characteristics. Below summarizes a few results from Apache Benchmark on our Resolve API using pre-mapped RIDs as input to the identity.resolve endpoint. A key characteristic of each test is that it uses ‘connection reuse’ to avoid the costly SSL setup time.
The first test runs the test within an AWS region that our API is deployed, us-east1 in this case. The median latency was 22ms, and mean around 27ms.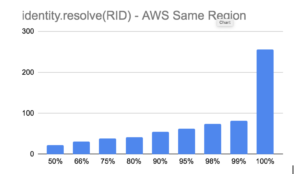
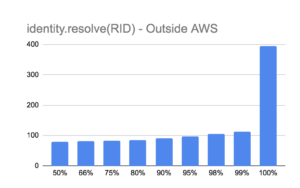
When benchmarked outside the walls of Amazon, it yields slower but still good performance where median latency was 79ms, and mean at 81ms.
See It In Action
To demonstrate a few simple examples with curl, we can display a common use case where a FullContact customer has two completely different systems. One system is a CRM managing all active customers, the other being a Loyalty Program system helping drive engagement with the brand. In this simple example, we load two systems into the Resolve API who are completely siloed from each other. Once loaded, the goal is to be able to better understand their customers. This example has an important “real world” twist where API is presented with an identifier that is currently unknown to the brand – the user’s B2C email.
Load CRM DB records via identity.map and recordID with a Business Email:
curl -s -HContent-Type:application/json \ -H"Authorization: Bearer xxx" \ https://api.fullcontact.com/v3/identity.map \ -d '{"<recordId":"crm:12345", "emails":["< first.last@b2b.com"]}' { "recordIds": [ "crm:12345" ] }
Load Rewards DB records via identity.map and recordId with a phone number:
curl -s -HContent-Type:application/json \ -H"Authorization: Bearer xxx" \ https://api.fullcontact.com/v3/identity.map \ -d '{"recordId":"rewards:TS012FH2", "phone":["<>13032223333"]}' { "recordIds": [ "rewards:TS012FH2" ] }
During an event on either system, the consumer interacts with the brand using their consumer-based email, we can see that the user is both an active customer (from the CRM) and a rewards member:
curl -s -HContent-Type:application/json \ -H"Authorization: Bearer xxx" \ https://api.fullcontact.com/v3/identity.resolve \ -d '{"emails":["first@gmail.com"]}' { "recordIds": [ "crm:12345", "rewards:TS012FH2" ], "personIds": [ "R0kavZ-q79TRs6ySys-KhIhIzag7iZUcGkcupicq6P0_W8sX" ] }
While not explicitly shown above the implied magic here is that 13032223333, first.last@b2b.com and first@gmail.com all share the same PersonID. If queried individually in the identity.resolve endpoint, they all return the same PersonID. Not only that, but any identifier connected to the Person record will do the same, just as the first@gmail.com shows. This is where the Identity Graph showcases its true power!
Resolve: A Bright Star in the Making
If you made it through the full series, I hope you gained some key takeaways that can be brought to the table on either the product or engineering side! I am greatly appreciative of the product and engineering teams for giving me the capability to write about the fantastic things we’re working on, and we hope you’ll continue to follow us as we dive deeper into other technical issues. We’re just at the beginning of a new journey as we work to redefine the consumer and brand relationship in a positive, secure, and privacy-focused way.
If you’re ever wondering about “changing it up”, let us know! Our teams at FullContact are technical and have very challenging problems to solve and we are looking to add curious, hard-working collaborators who love solving hard problems!
Post comments or questions as you have them, and follow our careers page as we open new roles! Thanks for reading!

