

FullContact Engineering: Cost Savings and Saving Our Bacon
Why Engineers Need to Consider the Cost of Cloud Computing
One of the benefits of cloud computing is the ease with which engineers can spin up infrastructure and achieve business goals rapidly. It’s also one of the shortcomings, especially when cloud providers make pricing confusing to understand as you start to use more and more services. The ability to spin up resource waste in seconds with a single `terraform apply` or button press is a battle every company has, whether they acknowledge it or not. Some companies are even creating dedicated roles and teams to control cloud costs.
I believe concepts like DevOps and FinOps are primarily cultural challenges. In the case of FinOps, this means that cloud costs are ideally everyone’s concern. While engineers shouldn’t concern themselves with the total monthly costs, we can and should think about the solutions we create from a cost perspective–and it doesn’t hurt to know what that monthly cost is either.
Anecdotally, it’s been my observation that most engineering departments consider costs only when needed, and in some places, it’s often never truly challenged by the business. While the Finance team will point out irregularities and challenge the need for exceeding our budget in a given month or two real lasting change does not usually occur as a result. Instead of being reactionary, we are now striving to engage in a way where costs are a consideration for solutions to our business challenges. When the cost of a solution becomes just another standard constraint through which we process our solutions, we adapt to hit the targets as best as possible.
Enter Project 🥓
As the world began to face financial uncertainty brought on by a global pandemic in early 2020, it was apparent that our cloud spend was on the rise and needed to be addressed in a more focused way than the occasional cost optimization here and there. We needed a concerted effort on cost savings that would make a meaningful and lasting impact. “Project Bacon” was born to save the company’s bacon.
It was decided that Project Bacon would be a one-week project, similar to a company hackathon where the entire engineering team would focus on how to save and reduce costs on their team. Like a hackathon, we brainstormed a list of ideas and projects for the teams to work on and let each engineer choose the team they wanted to be part of.
The brainstorming resulted in over 30 different savings opportunities that we organized into 8 different categories (or squads for teams to work on):
Object Storage and Cleanup
Object storage (S3) can easily become one of the largest cost drivers in your AWS account. As part of the project-bacon initiative, we had each team take a detailed look at its S3 usage and consider what data was necessary and what data could be cleaned up. In many of these cases, we found large data sets we could simply delete. In other cases, we applied lifecycle policy rules to clean up and delete data after a certain period of time. The combination of manual cleanup and lifecycle rules accounted for the majority of our cost savings during the initial project-bacon.
While it is best practice to create lifecycle rules on all of your important S3 prefixes there are times you either have so many prefixes to manage or you are not sure what the rules should be. In cases like this, you can opt to use the S3 Intelligent Access Tiering (IAT). When this tier is applied to your objects AWS will track how often your objects are accessed and attempt to keep them either in Standard or Infrequent Access to give you the best overall price. AWS charges a fee in order to keep track of this data but in general once this is applied you should start to realize savings after the first 30 days. We found that when we applied IAT to a bucket with more than 500 TB of Standard objects we saw a higher cost the first month as everything was being analyzed, but after the first month when the majority of objects were transitioned to infrequent access (IAT-IA) we saw approximately an 18% cost savings on that bucket.
Rightsizing and Modernizing
Each time AWS comes out with a new generation of EC2 instances they usually offer an incentive to upgrade to the newer ones through more competitive pricing (for example m4 to m5 instance types). While FullContact tends to stay on the latest family of instances there are times that instances are left running on the old family. Updating to the newer instance family and ensuring you are not using oversized instances (ones with more CPU or memory than your service requires) can result in large cost savings.
Reserved Instances
Making use of Reserved Instances (RIs) and the newer method of Savings Plans you can save a significant amount on your compute by making an upfront commitment to AWS on how much you will use over the next one or three years. One of our weekly scorecard metrics we track is the percent of non-on-demand compute usage ((RI costs + Savings Plan Costs + Spot Costs) / Total Costs). Our goal is for this number never to dip below 95%. We keep this metric in check by making sure that we renew Reserved Instances and Savings Plans when necessary and that large dynamic workloads are all running on Spot.
EMR Reducers
We use Elastic Map Reduce (EMR) Spark to run several of our Identity Graph and Batch file export jobs. While it is convenient to be able to spin up large clusters to instantly work on a certain project this flexibility can also lead to a lot of variability in our monthly spend. As part of this initiative we focused on looking for ways for each Spark cluster to become even more efficient including:
- Using more cost-effective instance types
- Auto-scaling clusters
- Ensuring each EMR cluster is tagged with Team and Project keys
- Tuning Spark jobs to use only the memory and CPU they need to get the job done,
- Running Spark on Kubernetes (EMR on EKS) to have more ephemeral clusters that can scale when needed.
The subject of tuning EMR is still ongoing and could be the subject of its own dedicated blog in the future.
Product Cleanup
We found that in our current environment where a few key APIs and features are being used by our customers there are other products that have fallen by the wayside and generally forgotten (except in our AWS bill). We worked with our awesome product managers to find and coordinate the deprecation of these older services so we could shut down the infrastructure and save our bacon.
Kafka streamliners
FullContact is a heavy user of Apache Kafka for real-time streaming operations. The streamlining process involved identifying duplicated Kafka clusters that had been created to support different teams or versions of Kafka and working to consolidate onto a larger single cluster managed through AWS MSK.
Bandwidth squad
Bandwidth costs are a somewhat hidden cost that can start to creep up on you if you aren’t paying close attention. AWS charges additional fees when your data traverses from one VPC to another, or from one Availability Zone to another. In many cases, you can architect your application to be aware of where it’s running and to prefer to send traffic to other instances in the same zone. As part of project-bacon, we experimented with the way our services discover and connect to our databases in RDS to prefer a replica running in the same availability zone. Doing this not only saves on our monthly bill but results in lower latency and higher performance for our applications.
The Creation of Costbot
Having a monthly budget, and then realizing you went way over it after the fact is no fun. Traditionally we were reliant on third-party tools to help us track and predict our monthly spend. In 2020 we decided to simplify and become leaner by reducing our dependencies on third-party tools and services. That’s why we came up with a simple app to give us a daily check-in on how our monthly spend is trending, and what is contributing to it. Costbot is a simple slack bot implemented as a Python Lambda that runs once a day and uses the AWS Cost and Usage Report (CUR) API to grab and display a few key metrics on our spend:
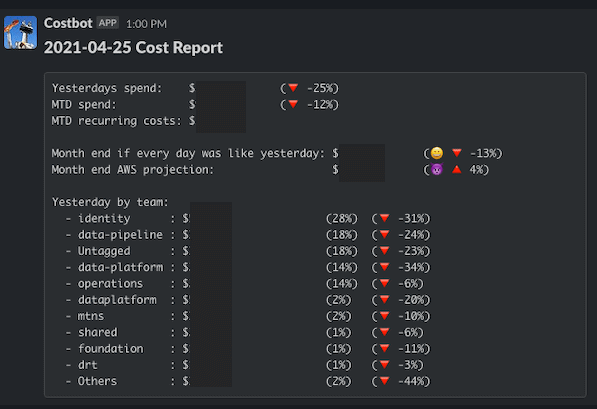
- Total spend yesterday (percent change)
- Month to Date Spend
- Month to Date recurring costs (covers the RI purchases that show up on the first of every month)
- Naive month-end project (If every day for the rest of the month had the same spend as yesterday)
- This can quickly point out days where you had large Spark clusters that are contributing to high spend
- Month-end AWS projection
- Yesterday’s cost break out by each team
While there are many existing tools out in the market that offer you similar features we found the approach of keeping it simple and making this information visible in our team Slack is really all we needed. We check in on our daily and monthly cost projections and strongly believe that you should too.
Results:
After Project Bacon, we made a giant leap forward and were able to reduce our monthly bill by approximately 20%. The largest savings we realized were in setting more aggressive retention policies to clean up unneeded data in S3 and purchasing Reserved instances to make sure that our on-demand usage stayed under 4%. Keeping your cloud costs in check is really a never-ending project and takes a shift in the way you think about writing, deploying, and managing your applications. To keep the project alive we continued to use the #project-bacon slack channel to communicate small-cost wins and keep each other accountable for increasing costs.
In summary, staying on top of your cloud costs is possible, but it’s complicated. It takes a concerted effort and behavioral change from the teams. While organizing a large one-time cost savings effort can have a large impact on your organization (as it did for ours) – what is really needed is a long-term shift where each member of the team is considering how what they are doing drives cost and what they can do to make their systems even more efficient. As teams have started paying attention to costbot we are starting to see more and more of that shift. In response to costbot the team will question why costs changed so much from the day before. These questions in turn have spawned conversations about how to run EMR clusters more efficiently, save money on S3 storage, and just how to have better cost-conscious designs from the start.

