

Prototyping the Future
My team and I had just completed demoing a powerful idea, rapidly prototyped over the span of just two weeks.
It demonstrated the ultimate power of fusing our Enrichment and Contact Storage technologies together, with a few flashy features thrown in for good measure. In essence, it empowered a user to provide multiple data points per enrichment request, create and manage subscriptions, customize views of the data, utilize large scale contact de-duplication and more.
The @FullContact Product, Engineering and Design Team is Amazing. My mind was seriously fucking blown today. pic.twitter.com/9LvWI4cVGM
— Bart Lorang (@bartlorang) March 9, 2017
As I stepped off the stage, I knew we had struck a chord with our CEO, Bart Lorang. In an open display of vulnerability, our fearless leader embraced me with tears streaming down his face and declared “This is why I have raised the millions of dollars for this company…”
The gamble on the two week prototype paid off and bought us enough rocket fuel for the next four months to build it out. Not only did we receive a green light and a gold star, but it appeared to have become a galvanizing force within the company, shifting the winds in our sails to focus more on our core Platform.
This blog is about my experience developing our NextGen APIs and how we went from an idea to prototype to release. It all started with customer obsession…
Customer Obsession
You may know FullContact as a Contact Management Application, or a set of APIs for People and Company Data, or maybe even both. In the former case, we have applications for a variety of platforms (browser, iPhone, Android, etc) to assist in simplifying your experience in managing the contacts from your personal networks. The application interacts with internal backend APIs to enable contact storage complete with various contact synchronization capabilities. Our Person and Company APIs harness the power of our identity resolution systems to turn simple identifiers (i.e. email, twitter handle, phone) into full profiles complete with a names, photos, social accounts, and more.
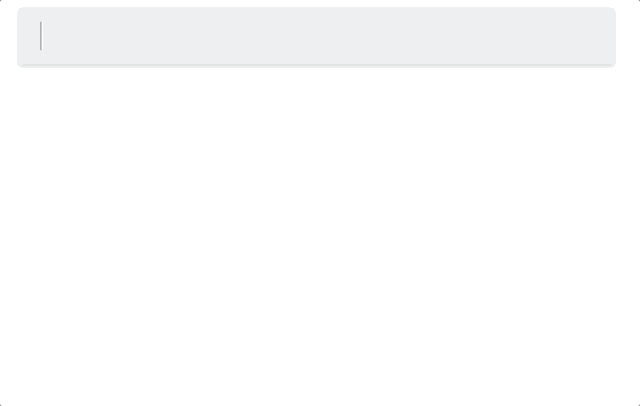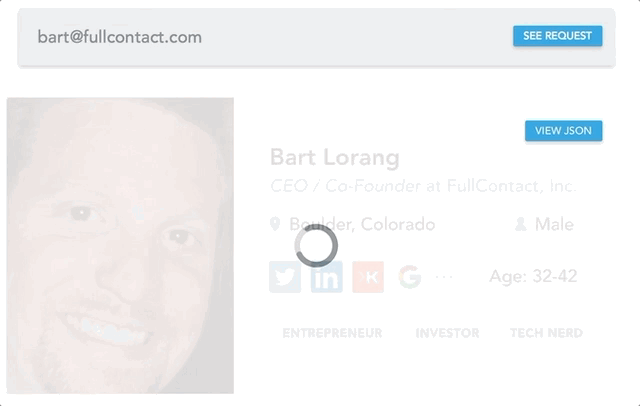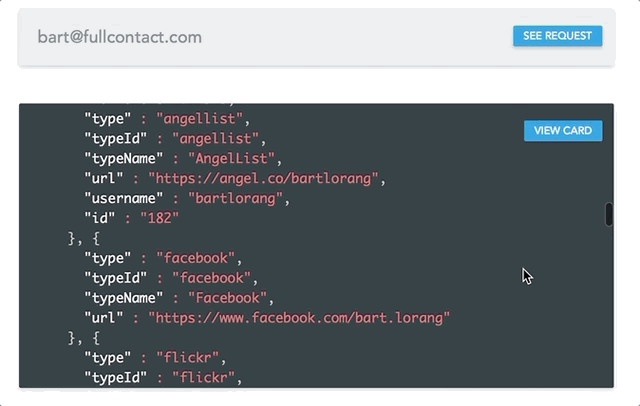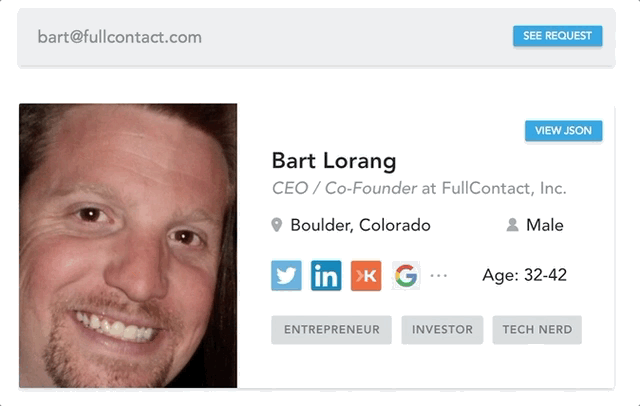
The journey to our v3 Enrich API, began in the early parts of December 2016 as I worked with our product team to help define the roadmap for 2017. We had lived off our V2 Person API for several years with minimal updates, which was starting to feel stagnated. Around the same time, we had an AddressBook API in Beta for storing Contacts. The API was awesome, but it had been built around the basic axioms of Contact Storage and was not very amenable to enrichment. Both APIs served a specific purpose, but they were inconsistent and limited in various ways.
In those late days of December, we were also looking outwards at the wonderful feedback our customers had offered over the years. Little by little, trends emerged around what the customer seemed to be asking for: some blend between our two core competencies, but at scale.
NextGen API = Large Volume * (Enrichment + Subscriptions +
Contact Storage + Duplicate Detection)
Enrichment
Customers love our enrichment APIs, in particular our Person API. Enrichment means that we are skilled at taking a small amount of data as input, such as an email address, and returning a more complete profile describing the contact details behind the identifier. Some of the common points of customer feedback revolved around the lack of ability to send more data points alongside an identifier. If provided, this could symbiotically aid in achieving more accurate results at higher match rates.
Secondly, customers had specific needs around the type of data they wished to pay for. Some customers were interested in the B2C aspects of a profile, leveraging social accounts for outbound communication, or as inputs to their machine learning algorithms. Others were interested in the B2B data such as work experience and demographic data. Marketing and sales organizations utilize the data for segmentation, cohort analysis, etc. Paying for an all-in-one solution was simple for us, but was not really what the customer desired.
Subscriptions
Related to basic enrichments, our customers are encouraged to proactively refresh their datasets. This is important to ensure they have the most up to date view of each profile, snagging job changes, changes to social accounts, updated interests and affinities, etc. Additionally, there are legal requirements around the visibility of a profile should the actual person claim it, enhance it, or simply opt out. Ultimately, this became a pain point which we could rectify by simply inverting the data flow from a poll model to a push model.
Contact Storage
One thing we had always strived for with our AddressBook offering was to expose an API to enable access to a contact datastore for customized apps and integrations. This is what our Beta API set out to accomplish. Our existing API customers had similar requests, but their ‘Address Books’ were not just a few thousand contacts, but rather on the order of 100s of millions. Since they were already enrichment API customers, the necessity to enrich their dataset was also a necessity.
Similarly, other customers imparted to us they wish they never had to deal with managing contacts. Historically, they had to define a schema, deal with storage, figure out the CRUD operations, normalization, security, etc. In most cases, the painful necessity was a major roadblock as it consumed lots of developer time.
Duplicate Detection
One of the hardest technological challenges that goes along with contact storage is the fact that there will inevitably be duplicates in the collection. For the AddressBook API, this was less of an issue since the world of contacts we had to detect duplicates in was capped to around a few thousand. In the new universe of 100s of millions of contacts, the problem was completely different. To be able to detect duplicate contacts in a sea of 100s of millions of highly unique contacts, at near real time, is an incredibly challenging engineering problem. But, when done correctly, we can assist the customer in identifying their true contacts; ultimately saving them pain and money.
NextGen API Prototype for the Win
Once we had the list of concepts compiled, we wanted to see if we could combine them into a suite of NextGen APIs which felt natural. Something ergonomically beautiful. Something which shielded the complexity and nuanced nature of contacts from our customers. The question was whether the result would be easy to use and understand.
We could have spent months designing it all up front, arguing about the various aspects of the endpoints and behaviors, but the result would have gone unproven in the market for months, and likely have the smell of ‘designed by committee’.
No, we wanted to see it in action. Based on the formula, we crafted some high level specifications and features requests and gave the team two weeks to build it. Over the course of those following weeks, the team split up the pieces of functionality and rapidly constructed a set of API endpoints to fulfill the specs. In a final last minute tweak, we decided to build up a simple UI to better demonstrate our newly constructed system. We didn’t want to lose our audience by forcing them to visually parse JSON, but rather illustrate the raw horsepower through a set of dynamic pages. Ultimately, the UI proved to be an integral component to the prototype.
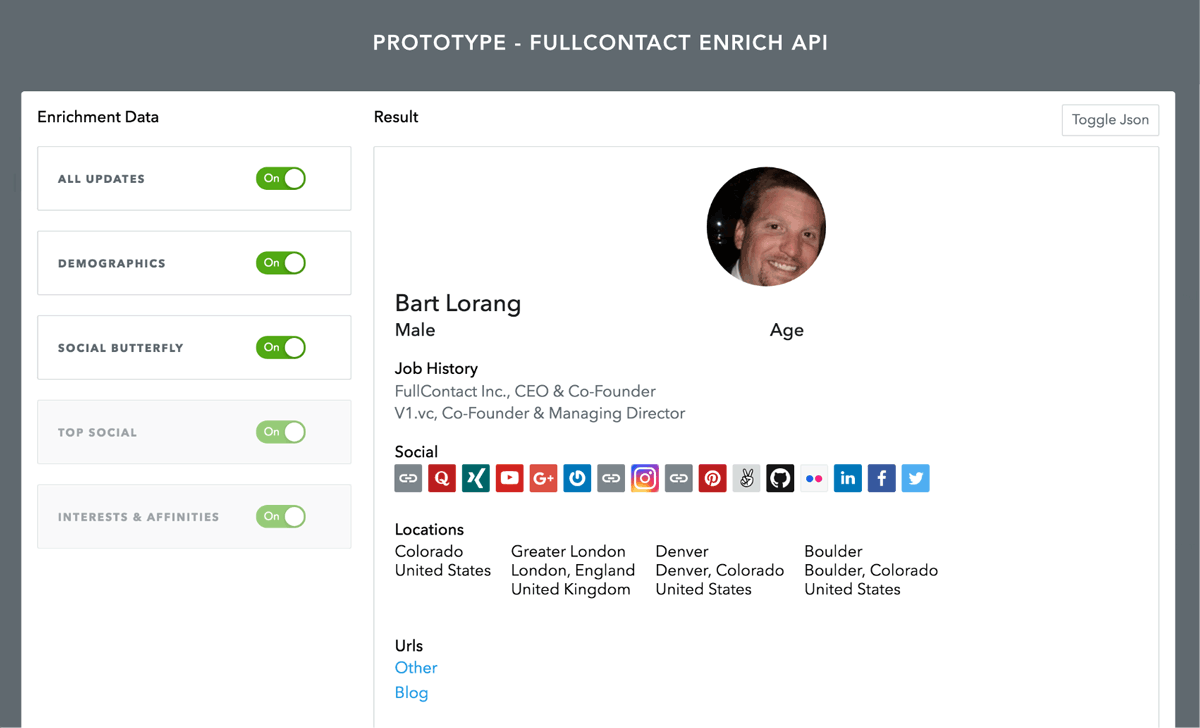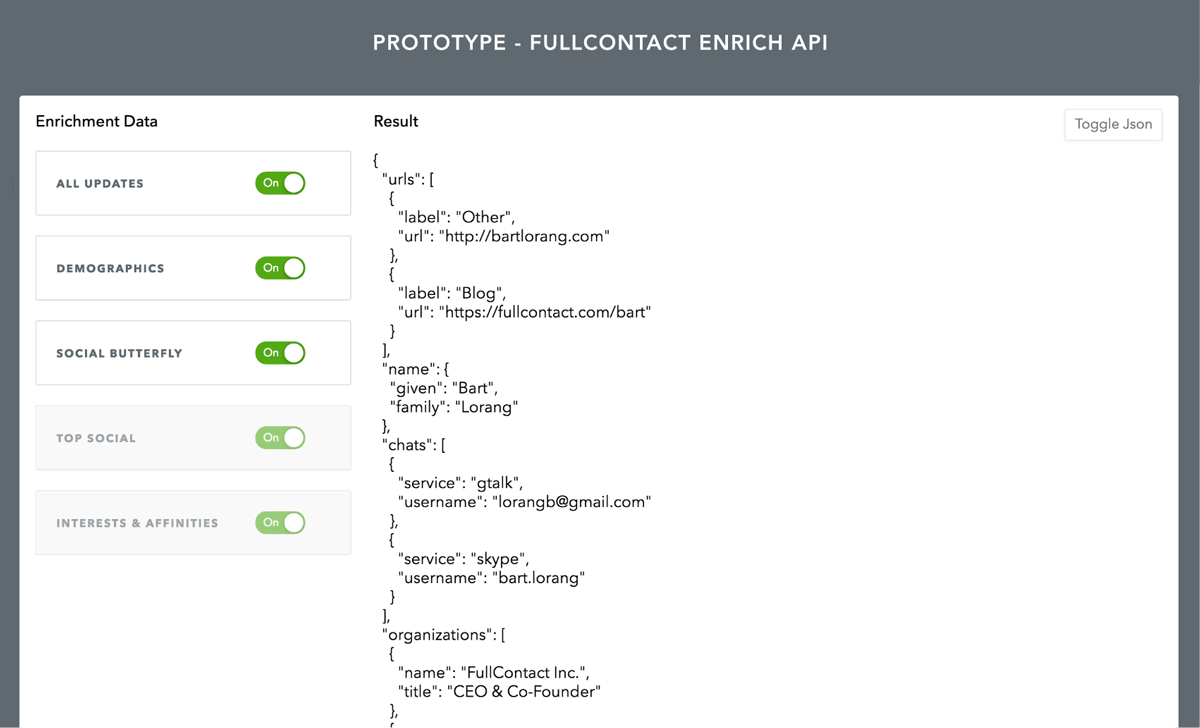
Doing the prototype reminded me of a few things I had almost forgotten over the years. First, building something in a total sandbox can reattach one’s wings of creativity. The team impressed me on so many levels as they took a series of abstract ideas and implemented them in better ways than I had even considered. Second, the sandbox allowed us to temporarily revert back to the Wild West of Cowboy Coding — being free to forget about correctness and testing. Last but not least, we were able to truly understand the scope and true nature of the problem at hand. With the prototype in hand, we could now showcase the results to our customers and gain further feedback on whether we were hitting the right notes.
Over the course of the next 4 months, we leveraged our learnings from the prototype and built out much of the behavior we trialed in March and were able to formally allow access to a few lucky customers!
The biggest lesson I relearned throughout this project was that you cannot effectively build large systems without being nimble, dynamic and iterative. Prototyping a series of concepts, based on seemingly disparate sets of customer feedback, will help both your product and engineer teams hone in on the true direction you can and should take. Don’t get stuck in the rut of trying to figure everything up front; you’ll be too slow and likely get it wrong!
Recent Blogs
-
 September 21, 2023 Discover How FullContact is Building Trusted Customer Relationships through Snowflake's Native Application Framework Customer 360, Website Recognition, Identity Resolution
September 21, 2023 Discover How FullContact is Building Trusted Customer Relationships through Snowflake's Native Application Framework Customer 360, Website Recognition, Identity Resolution -
 September 20, 2023 Transform Your Customer Experience with FullContact Customer Recognition and Boost Your Conversions Website Recognition, Identity Resolution
September 20, 2023 Transform Your Customer Experience with FullContact Customer Recognition and Boost Your Conversions Website Recognition, Identity Resolution -
 September 14, 2023 FullContact Recognized as a Leader in Snowflake’s Modern Marketing Data Stack Report FullContact News, Partnership
September 14, 2023 FullContact Recognized as a Leader in Snowflake’s Modern Marketing Data Stack Report FullContact News, Partnership