

(Re)Driving The Databus
In this blog, we’ll explore the backend processes and architecture that power Resolve while discussing some challenges we faced along the way.
When designing FullContact’s newest product, Resolve, we borrowed several concepts from our Enrich platform and adapted them to support key differences between the two products.
Our existing enrichment platform, which primarily serves read-only data, uses HBase as its primary data store. A common task automated through Airflow when new datasets are periodically ingested or refreshed internally is to completely rebuild the HBase cluster from the underlying data by generating HFiles via EMR and creating a new read-only database. This enables us to “online” new datasets.
The Airflow DAG at a high level looks like this:

Steps for Launching new HBase via Airflow
In fact, multiple large internal databases here at FullContact use this process. This lets us easily leverage our data pipeline for big data processing and switch databases with new and/or refreshed identifiers with zero downtime. We took a similar approach for our Resolve platform. However, with data being written by customers instead of just reading internal data, we were presented with several challenges.
Before we continue, it’s also worth mentioning another key difference with data storage–we decided to use Cassandra in place of HBase, the common database for key FullContact platforms.
Reaching back to computer science theory, the CAP theorem tells us for any database, you can provide at most two of the three properties: Consistency, Availability, and Partition tolerance. HBase covers C and P of the CAP Theorem, allowing consistent reads and partition tolerance while Cassandra covers A and P through consistent hashing and eventual consistency.
For Enrich, all customer’s queries read from a statically compiled database containing enrichment data. Given the lack of scalability needs and desire to have very consistent data, we chose HBase.
We intentionally sacrificed consistency for partition tolerance for our Resolve product since customers accessing their individual FullContact Identity Streme™ have higher volumes of dynamic requests. As we explore below, customer records are written to two places: the Cassandra database and archived to S3.
Additionally, when PersonIDs are generated, they’re consistently generated for a given individual customer’s account. Each customer provides Record IDs on their side, so in the worst case, if Record IDs are re-mapped or PersonIDs are re-generated, we can again minimize the consistency concern. Giving up a small amount of consistency lets us focus our attention on A and P: Availability and Partition tolerance with Cassandra.
Cassandra also gives us what we need:
- Scale: The ability to scale by adding nodes to the cluster while simultaneously keeping simple (not needing HDFS) and keeping costs in check.
- Write Performance: Cassandra can write faster than HBase. In Resolve, persisting customer identifiers (Person IDs and Record IDs) are important. While reading them is also important, we don’t require the level of consistency provided by HBase.
- Improved Experience: The developer experience and one-off queries can be more friendly using Cassandra Query Language (CQL) and the Cassandra data model over HBase.
Resolve Platform Architecture
For every customer query that comes in, we use our internal Identity Graph to assign the query a FullContact ID (FCID) — the standard internal identifier we use. The FCID allows us to associate various contact fragments (phone number, email, name + address, etc.) to the same person. Once input data is resolved to an FCID, data is written to:
- Cassandra for real-time reads and writes – querying by FCID, PersonID, and Record ID.
- Kafka – Encrypted customer data are written for long-term storage and archival (aka the Databus).
PII is never stored in Cassandra. As little data as possible is stored in the database for security purposes and to keep storage costs in check. We never store PII or sensitive customer data at rest in the Resolve database and never in plaintext in S3.
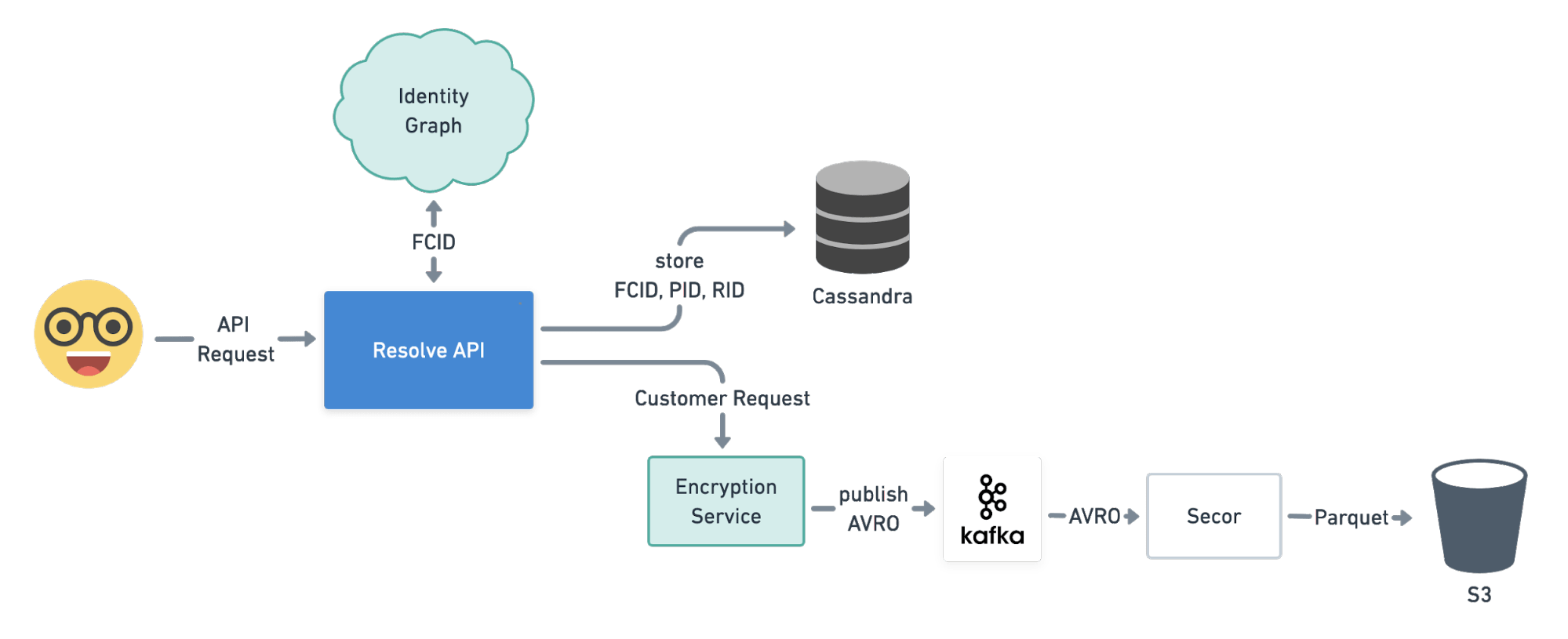
Our Resolve Platform
Rebuilding the Database
Our Identity Graph continuously evolves–both the algorithms behind it, as well as data. As new data is ingested into the graph and connections are made, FCIDs can and do change.
Let’s say our graph sees an email and a phone number as two different people, therefore assigning two different FCIDs. As additional observations of the email address and phone number are found, the graph may determine they are actually the same person and ultimately point to the same FCID. The reverse can also be true — say with a family or shared email address: our graph may first see an email and associate it to a given person, where subsequent signals point to this being two separate people. In this case, the one FCID would split into two FCIDs. To ensure customer PersonIDs and Record IDs always point to the correct person, we periodically rebuild the database from the Databus archive.
As mentioned earlier, customer input is written to Kafka, which then gets archived to S3 using secor. Kafka data is only retained for a few days to not spend an excessive amount of money for storage for our Kafka setup.
To rebuild a database, the first step in ensuring FCIDs are up to date is to decrypt customer records. As part of load testing during development, we were able to query our internal decryption service at a rate of 1.1 million records / second — a speed that lets us reasonably call our decryption service directly from a Spark job. Theoretically, we’re able to decrypt one billion records in just over 15 minutes!
Offline Data, Online Database
Once customer records have been updated with new FCIDs, we build database files “offline.” While the typical use case of loading data to Cassandra is streaming records into a given instance, we would pre-build Cassandra SSTables and upload to S3 to maximize data load performance. Copying SSTables directly to each node lets us avoid the performance hit of compaction running in the client’s background and overhead. Since Resolve data is stored under different sets of identifiers (FCID, Record ID, PersonID), each record would require an INSERT statement to be executed if streamed to the cluster, whereas by doing this “offline” in Spark, we can generate the INSERTS in memory for each table while reading the dataset only once.
The key to generating SSTables and avoiding unnecessary compaction is properly assigning token ranges to each Cassandra instance (The Last Pickle covers token distribution in a blog post here). Without this step, as soon as Cassandra starts up and realizes new SSTables, it will immediately shuffle records across the network until data resides on its respective nodes. By getting this correct, Cassandra sees new SSTables and doesn’t need to move any data around, preventing read/write performance impacts.
We have a Jenkins job that can take in: EC2 node types, EBS volume size, number of nodes, and location of the SSTables, which then kicks off an Ansible Playbook to:
- Launch EC2 nodes and attach EBS volumes.
- Install and set up Cassandra.
- Copy over SSTables to each individual.
- (Re)start Casandra.
The database starts up in seconds and can immediately serve requests!
Catch Up Time
The biggest challenge we ran into was keeping the recently created database up to date while additional writes are occurring in the current database. By the time our Spark data pipeline runs through with archived Kafka data, our database is already out of date — missing the last few hours of data — data that hadn’t yet been archived to S3 but was written to Kafka. Secor will batch messages and write to S3 once it has accumulated a set number of messages or the batch time has been reached (i.e., 10000 messages or 10 minutes).
While most data has been accounted for, these recent records are still important to keep in a new database. We are only concerned with the tiny fraction of recent records which haven’t been accounted for in the database rebuild process. Since Secor tracks which offsets it has written to S3, and the rebuild process interacts with the same S3 data, we capture the Kafka offsets Secor stores from Zookeeper to deal with these records.

Driving The Databus: Creating a New Database
We investigated several technologies to solve this issue and ultimately decided on Spark Structured Streaming. While evaluating our options, we did look at Spark Streaming, but found that it isn’t designed to run in a batch context from the ‘start’ offset to an ‘end’ offset. Spark Streaming is typically used in a consume-and-then-produce fashion, so we accepted the slight lag tradeoff that came with Structured Streaming.
Once the new database has been created from the SSTables and our application has been deployed with the updated configuration, we trigger our Spark job to write the remaining records to the new Cassandra. It will run from the latest Secor offset captured to the latest offset on the Kafka topic when the Spark job is triggered. There will be a slight lag between the service deploy and the job trigger, but after the Spark job is completed, the database will not have dropped any requests. This process can be run repeatedly–just before the new database is deployed to production to reduce the window databases are not in sync as well as just after we deploy to make sure all have been written to the new database.
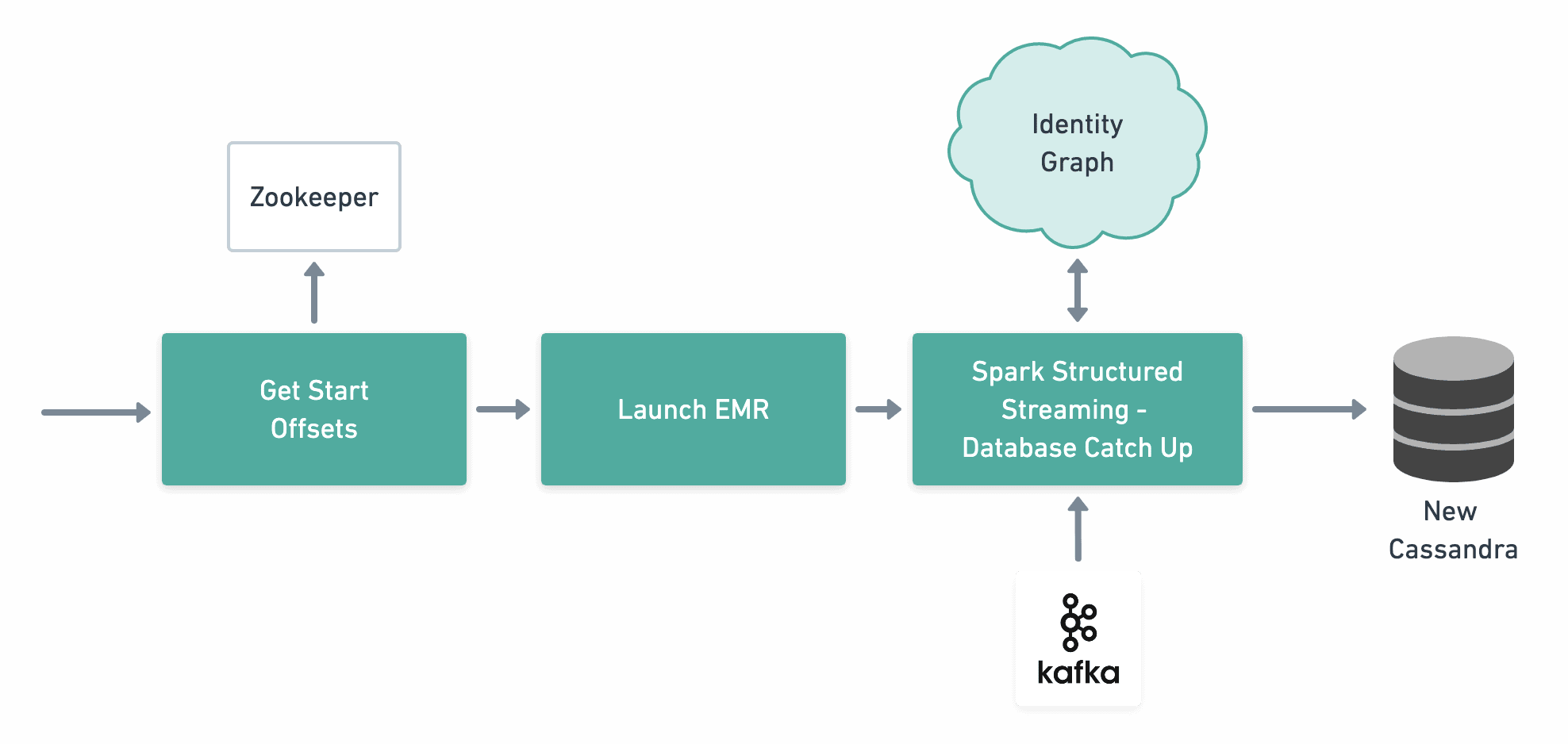
Database Catch Up
Database Rebuild Performance
Our model of archiving and then using Spark jobs to rebuild the database with no downtime has proven to be extremely valuable as we have been actively developing the platform. Some major schema upgrades to support new features have been trivial as we can transform the data archive to keep up with enhancements.
Resolve – Building a new Database: (~700MM rows)
-
- EMR setup: 8 minutes
- Decrypt data from databus, compact, and prepare data for internal data pipeline run: ~ 2 hours — including 700MM+ decrypts *
- Pipeline run: 3 hours (Data must be resolved to new FCIDs)
- Create Cassandra Cluster with Ansible: 10 minutes
- Build SSTables: ~2 hours [Input: ~45MM Rows, Output: ~300MM rows
- Load SSTables: 45 minutes **
- Total: ~6 hours
* While we have proved a speed of 1.1 million decrypts per second through our internal decryption service from Spark, our current data scale does not require us to run at this speed. We feel good about our ability to scale decryption as data sizes grow.
** We are limited by using cheaper EC2 instances with slower EBS volumes. As Resolve data needs grow, we’ll move to faster instances
The SSTable Build and Load took approximately 2.75 hours, which would require us to stream data into Cassandra at 30k/second [300MM records / (60 seconds/minute * 60 minutes/hour * 2.75 hours) = 30K/second inserts. Given the relatively inexpensive EC2 instances we’re running, with EBS drives limiting I/O, we are only able to stream inserts at about 10% of this speed (~3k/second) with active background compaction happening.
From a cost perspective a rebuild costs us roughly (not including network traffic) :
- EMR Cluster: 5 hours * ([ 64 instances * i3.2xlarge (Core) * $0.20/hour(Spot) ] + [ 1 instance * i3.large (Master) * $0.31/hour ]) = ~ $66
- S3 Cost: 900GB * $0.023 per GB (standard) = ~ $20
- Running a Second Database 5 hours * ( 3 nodes * c5.2xlarges * $0.34/hour + 2TB EBS/hour: 3 * $200 GB-month/30 days/24 hours) = ~$9
- Total: $95
What’s Next?
Check back next month for more details around our latest projects: scaling up our resolve platform with ScyllaDB in place of Cassandra and the challenges we’ve overcome to achieve API and Batch parity to better serve our Resolve customers. Early metrics have shown we’re able to run Scylla on the same hardware at 8X queries per second!

